Understanding K, Q, V: An Intuitive Breakdown
Sometime ago, I was talking to one of my friends about the KV cache. Later, sitting on the Caltrain, I kept chasing the same line of thought — but this time from an information retrieval standpoint. I wanted to share some of it here. Ideally, I want to explain my understanding of Attention without any fancy algebra or a wall of matrices. All of that is covered very well elsewhere. We'll focus on the intuitions instead.
Attention - From the lens of a search engine
Let us travel back 15 years, fire up the browser and go to a search engine and pose a question. Let us call it a Query (Q). Super duper early search engines worked on the principles of keywords. A website would decide on some keywords and advertise it. Let us call it Key (K). If there was enough similarity between the Query (Q) and Key (K), we would keep it as a likely result. We would go through a bunch of keys and get a bunch of likely results. We would decide based on the similarity, the ranking and present them. But what would we present? We would present a link to that webpage. Or the content of that webpage. The actual content and not the keywords. We should call it Value (V).
We would say the following --
| Matrix | Role | Description |
|---|---|---|
| Query (Q) | "What am I looking for?" | A search query — this token asks a question to all other tokens |
| Key (K) | "What do I contain?" / "What can I offer?" | A label/tag — this token advertises what information it holds |
| Value (V) | "If I'm selected, here's my actual content" | The payload — the actual information passed along if this token is deemed relevant |
During early search engine days, we would formulate similarity as a dot product. That's exactly what happens in the attention layer too. We get the dot product of Q and K. Their dot product tells us the similarity of a vector in Q and a vector in K. Fancy folks call the resultant matrix The Attention Matrix. It tells us what Q and K are attending to each other or similar to each other.
Since the values could be all over the place, one wants to normalize the above matrix. People found out square root of the dimension is a good number to divide with. I'll not go into that here as that requires understanding the distribution of the tokens and how their variance looks like.
The Library Analogy
Let us imagine ourselves to be in a big library. The kind of library you see in The Discovery of Witches TV show, haha.

Bodleian Library from A Discovery of Witches. Picture every book on these shelves as a token.
Each book can be seen as having two things: a spine label describing what it contains, and the actual pages inside with the real content.
| Library concept | What it translates to |
|---|---|
| A visitor's question at the help desk | Query |
| The spine labels on every book | Keys |
| The actual pages inside each book | Values |
How it works step-by-step:
- A visitor walks up to the help desk and asks a question (Query)
- The librarian scans the spine labels (Keys) of every book on the shelf and asks "how relevant is each book to this question?" — that's the dot product Q·K
- The librarian doesn't just grab a single book — they assign a relevance score to every book on the shelf (softmax). One book might be 70% relevant, another 25%, and the rest share the remaining 5%
- The librarian then pulls the actual pages (Values) from ALL the books, weighted by those relevance scores, and writes up a blended answer
The output is a blended summary:
answer = 0.70 × (pages of book 3) + 0.25 × (pages of book 7) + 0.03 × (pages of book 1) + ...
This is what makes attention powerful — it synthesizes information from multiple books in a single step, rather than being forced to pick just one.
To be clear, the 4th part is where our search engine and library analogy falls apart a little. The librarian, instead of getting us the most relevant book, gives us an answer that is a blended output of all the relevant pieces from various books! Hence... Generative!
Multi-Head Attention (MHA)
With 32 heads, it's like the library has 32 specialist librarians, each sitting at their own desk with their own personal catalog of the same collection of books. What does this mean and how does it manifest? For a key that shows up similar, one librarian might synthesize something different from another librarian.
Example: If we have something like - "whatcha doin?!". One librarian might generate content that is colloquial and conversational. Another librarian might generate content that is super positive and over the top. The blended answer will be a combination of different heads expressing different things.
The visitor asks the same question at all 32 desks. Each librarian:
- Has access to the same books on the shelves
- But each librarian has built their own catalog system (their own W_k, W_q, W_v weight matrices)
- So they each wrote their own spine labels (Keys) emphasizing what they think matters about each book
- And curated their own reading notes (Values) summarizing what they think is useful to pass along
The 32 answers get concatenated and mixed through a final synthesis step - output projection (W_o) — like collecting all 32 specialist opinions and writing a single unified answer for the visitor.
Detailed Example: What Each Librarian's Catalog Looks Like
Example Sentence: "Three parts of Earth are Crust, Mantle and ___" (9 tokens ~> 9 books on the shelf)
The model needs to predict the next token. Each librarian catalogs the same 9 books, but the spine labels (Keys) and reading notes (Values) reflect that librarian's specialization. How does this manifest? I asked Gemini about it and it had a lot to say actually. Let's look what happens with a few of the 32 heads...
Librarian 3's catalog: "Syntactic Structure" - Head# 3
| Book (token) | Spine label (Key) | Reading notes (Value) |
|---|---|---|
| Book 1: "Three" | "numeral modifier" | "quantifies the following noun" |
| Book 2: "parts" | "subject noun, plural" | "the main topic of the sentence" |
| Book 3: "of" | "preposition, partitive" | "indicates composition" |
| Book 4: "Earth" | "proper noun, object of prep" | "completes the prepositional phrase" |
| Book 5: "are" | "linking verb, present" | "connects subject to predicate list" |
| Book 6: "Crust" | "predicate noun, list item" | "first item in a list" |
| Book 7: "," | "list delimiter" | "more items follow" |
| Book 8: "Mantle" | "predicate noun, list item" | "continuation of list" |
| Book 9: "and" | "coordinating conjunction" | "signals the final list item is next" |
When "and" (book 9) sends a Query like "what syntactic pattern am I completing?", this librarian scores "Crust" and "Mantle" highly (predicate nouns in a list) and the comma (list delimiter) — recognizing that "and" is the conjunction before the final item in a list of predicate nouns.
Librarian 12's catalog: "Semantic Categories" - Head# 12
| Book (token) | Spine label (Key) | Reading notes (Value) |
|---|---|---|
| Book 1: "Three" | "quantity, cardinal" | "the count is three" |
| Book 2: "parts" | "component, division" | "subdivisions of a whole" |
| Book 3: "of" | "composition relation" | "what follows is the whole" |
| Book 4: "Earth" | "planet, geological body" | "a layered rocky planet" |
| Book 5: "are" | "equivalence relation" | "what follows defines the subject" |
| Book 6: "Crust" | "geological layer, outermost" | "the thin rocky outer shell" |
| Book 7: "," | "punctuation" | (near-zero signal) |
| Book 8: "Mantle" | "geological layer, middle" | "the thick semi-solid middle layer" |
| Book 9: "and" | "signals final member" | "one more of the same category coming" |
When "and" sends a Query like "what kind of thing comes next?", this librarian scores "Crust" and "Mantle" highly (both geological layers) and "Earth" highly (the geological body being divided). The blended answer screams "a geological layer of Earth" — and since the outer and middle layers are listed, the missing one is obvious. This is how the model knows to predict "Core".
Librarian 20's catalog: "Who's Near Whom" - Head# 20
| Book (token) | Spine label (Key) | Reading notes (Value) |
|---|---|---|
| Book 1: "Three" | "shelf position 1" | "book at position 1" |
| Book 2: "parts" | "shelf position 2" | "book at position 2" |
| ... | ... | ... |
| Book 7: "," | "shelf position 7" | "book at position 7" |
| Book 8: "Mantle" | "shelf position 8" | "book at position 8" |
| Book 9: "and" | "shelf position 9" | "book at position 9" |
This librarian doesn't care about meaning — they just catalog by shelf position. A question from "and" (book 9) would score "Mantle" (book 8) highest simply because it's the immediate neighbor. This helps the model pick up local context: whatever comes after "and" should relate to what came just before it.
Librarian 27's catalog: "Repeated / Parallel Structure" - Head# 27
| Book (token) | Spine label (Key) | Reading notes (Value) |
|---|---|---|
| Book 1: "Three" | "quantity marker" | "sets expectation: 3 items" |
| Book 2: "parts" | "category label" | "names what's being listed" |
| Book 3: "of" | "relation marker" | "links parts to the whole" |
| Book 4: "Earth" | "the whole" | "the thing being subdivided" |
| Book 5: "are" | "list introducer" | "a list follows" |
| Book 6: "Crust" | "list member #1" | "first of the series" |
| Book 7: "," | "separator" | "separates list members" |
| Book 8: "Mantle" | "list member #2" | "second of the series" |
| Book 9: "and" | "final separator" | "precedes list member #3" |
Here "and" (book 9) queries "what pattern am I part of?" This librarian scores the comma highly (a parallel separator) and "Crust", "Mantle" as parallel list members. Crucially, it also scores "Three" highly — the model learns that 3 items were promised but only 2 have appeared, so one more must follow.
The Super Critical Insightful Idea Here
Concretely, the same token sent its query to 32 heads and —
- Head 03's spine label says "proper noun, object of preposition"
- Head 12's spine label says "planet, geological body"
- Head 20's spine label says "shelf position 4"
- Head 27's spine label says "the whole"
These are 4 different Key vectors for the same token, produced by 4 different W_k matrices. Each librarian labels the same book differently, advertising a different facet of what "Earth" is, depending on what that librarian learned to care about.
And notice how all four librarians converge to help the token "and" and predict what comes next — each contributing a different reason why "Core" is the next token:
- Head 03 says: "syntactically, a final predicate noun is expected here"
- Head 12 says: "semantically, the next word should be a geological layer of Earth"
- Head 20 says: "positionally, look at 'Mantle' right before you for local context"
- Head 27 says: "structurally, three items were promised and only two have appeared"
Together, they realize the blended answer should be "Core". And they output exactly that.
Multi-Query Attention (MQA)
MHA is powerful, but expensive. During inference, every generated token requires storing each librarian's catalog in a KV cache. With 32 librarians, that's 32 separate sets of spine labels and reading notes kept in memory — and for long sequences, this becomes the bottleneck.
Shazeer (2019) proposed a radical simplification: what if all 32 librarians shared a single catalog?
In MQA:
- Each librarian still formulates their own question (each head has its own W_q → own Query)
- But there is only one shared catalog — one set of spine labels (Keys) and one set of reading notes (Values), produced by a single shared W_k and W_v
What this looks like with our example
There's now only one catalog for "Three parts of Earth are Crust, Mantle and":
| Book (token) | Spine label (Key) | Reading notes (Value) |
|---|---|---|
| Book 1: "Three" | "numeral" | "a count" |
| Book 2: "parts" | "noun, plural, subject" | "the main topic" |
| Book 3: "of" | "preposition" | "relates to a whole" |
| Book 4: "Earth" | "proper noun" | "a planetary body" |
| Book 5: "are" | "verb, linking" | "equates subject to list" |
| Book 6: "Crust" | "noun, geological" | "a layer name" |
| Book 7: "," | "delimiter" | "list continues" |
| Book 8: "Mantle" | "noun, geological" | "a layer name" |
| Book 9: "and" | "conjunction" | "final item follows" |
The spine labels and reading notes are now general-purpose — they can't specialize the way individual librarians' catalogs could in MHA. Notice how "Crust" and "Mantle" both get the same generic label "noun, geological" — this single catalog can't distinguish syntax from semantics from position. But all 32 librarians still ask their own questions using this shared catalog:
- Librarian 3 asks a syntax-focused question => gets a syntax-weighted blend from the shared reading notes
- Librarian 12 asks a semantics-focused question => gets a semantics-weighted blend from the same notes
- Librarian 20 asks a proximity-focused question => gets a proximity-weighted blend from the same notes
The diversity now comes entirely from the Queries, not from the spine labels or reading notes.
Looking at The trade-off Here
| MHA (32 librarians) | MQA | |
|---|---|---|
| Query matrices | 32 distinct W_q | 32 distinct W_q |
| Key matrices | 32 distinct W_k | 1 shared W_k |
| Value matrices | 32 distinct W_v | 1 shared W_v |
| KV cache size | 32 catalogs | 1 catalog |
| Expressiveness | Each librarian catalogs differently | All librarians read the same catalog |
The KV cache shrinks by 32×, which is a massive win for inference speed and memory. But the shared catalog is now a jack-of-all-trades — it lost its ability to specialize! This can hurt quality, especially on tasks that benefit from diverse attention patterns.
Grouped-Query Attention (GQA)
Ainslie et al. (2023) observed that MQA's quality loss was sometimes too steep, but MHA's memory cost was too high. The solution: a middle ground.
In GQA, the 32 librarians are split into teams (say, 8 teams of 4 librarians each). Each team shares one catalog, but different teams get different catalogs.
The analogy we wish to make here
Instead of 32 librarians with 32 catalogs (MHA) or 32 librarians with 1 catalog (MQA), the library has 8 department catalogs, each shared by a team of 4 librarians:
- Syntax department catalog (shared by Librarians 1–4): labels books by grammatical role
- Semantics department catalog (shared by Librarians 5–8): labels books by meaning and category
- Proximity department catalog (shared by Librarians 9–12): labels books by shelf position
- ... and so on for 8 departments
Within each department, the 4 librarians share the same spine labels (Keys) and reading notes (Values) but still ask their own questions (Queries). Across departments, the catalogs differ — so the library retains some of MHA's ability to index books in diverse ways.
What this looks like with our example
Syntax department catalog (shared by Librarians 1–4):
| Book (token) | Spine label (Key) | Reading notes (Value) |
|---|---|---|
| Book 2: "parts" | "subject noun, plural" | "the main topic of the sentence" |
| Book 5: "are" | "linking verb, present" | "connects subject to predicate list" |
| Book 6: "Crust" | "predicate noun, list item" | "first item in a list" |
| Book 8: "Mantle" | "predicate noun, list item" | "continuation of list" |
| Book 9: "and" | "coordinating conjunction" | "signals the final list item" |
Semantics department catalog (shared by Librarians 5–8):
| Book (token) | Spine label (Key) | Reading notes (Value) |
|---|---|---|
| Book 4: "Earth" | "planet, geological body" | "a layered rocky planet" |
| Book 6: "Crust" | "geological layer, outermost" | "the thin rocky outer shell" |
| Book 8: "Mantle" | "geological layer, middle" | "the thick semi-solid middle layer" |
| Book 9: "and" | "signals final member" | "one more of the same category" |
Librarian 1 and Librarian 4 both use the syntax department catalog, but Librarian 1 might ask "what list pattern am I in?" while Librarian 4 asks "how many items were promised?" — different questions, same catalog.
GQA as the general framework
| Configuration | Catalogs | What it is |
|---|---|---|
GQA with num_kv_heads = 32 | 32 | = MHA (every librarian has their own catalog) |
GQA with num_kv_heads = 8 | 8 | Typical GQA (8 department catalogs, 4 librarians each) |
GQA with num_kv_heads = 1 | 1 | = MQA (all librarians share one catalog) |
GQA gives model designers a tunable knob between MHA's expressiveness and MQA's efficiency. In practice, models like Llama 2 70B and Mistral use GQA with a small number of KV heads (often 8), getting most of MQA's memory savings while recovering much of MHA's quality.
Multi-head Latent Attention (MLA)
DeepSeek-V2 (2024) took a fundamentally different approach to the KV cache problem. Instead of asking "how many librarians should share a catalog?" (the GQA knob), MLA asks: "what if we don't store full catalogs at all — and store a tiny compressed index card instead?"
The idea we want to hammer here
In MHA/GQA/MQA, the KV cache stores full spine labels (Keys) and reading notes (Values) — fully written out and ready to use. MLA replaces this with low-rank compression:
- Each book's information gets distilled down into a small index card (the latent vector)
- Only this index card is filed away — it's much smaller than full catalog entries
- When a librarian needs to answer a question, the index card is expanded back up into full spine labels and reading notes for all librarians, on the fly
The idea is to create a learnable compression matrix that compresses KV cache into a super tiny representation. Do the same for Q vector as well. Transfer Q into a latent space of much smaller dimension through a learnable transformation.
The library analogy
Imagine the library hires a master archivist who reads every book and writes a tiny compressed index card for each one — just a few dense keywords that capture the essence. All 32 full catalogs are then discarded, and only the index cards are kept on file.
When a librarian needs to answer a visitor's question:
- The archivist pulls out the relevant index card
- The card gets expanded back into a full spine label (Key) and reading notes (Value), customized for whichever librarian is asking
- The librarian uses these reconstructed entries to answer the question as usual
The insight we should have: different librarians can reconstruct different catalog entries from the same index card. The expansion step uses librarian-specific projection matrices, so Librarian 3 reconstructs syntax-focused labels while Librarian 12 reconstructs semantics-focused labels — all from the same compressed card.
Concretely, if the model size is 4096 and we have 32 heads, we will have each head's dimension as 128.
In the case of MHA, we would have stored 4096 + 4096 = 8192 numbers -> KV cache. We would also have stored 4096 values for Q vector.
In the case of MQA, we would have stored 128 + 128 = 256 numbers -> KV cache. We would also have stored 4096 values for Q vector.
In the case of GQA, we would have stored 1024 + 1024 = 2048 numbers -> KV cache. We would also have stored 4096 values for Q vector.
In the case of MLA, we would have stored 512 numbers -> KV cache. We would also store Q as 1536 numbers.
MLA uses 6.25% of MHA's memory when it comes to KV cache.
We are ignoring RoPE for the sake of simplification.
What this looks like with our example
For the book "Earth", instead of storing:
| MHA stores | MLA stores | |
|---|---|---|
| Librarian 3 | Label: "proper noun, object of prep" + Notes: "completes the phrase" | |
| Librarian 12 | Label: "planet, geological body" + Notes: "a layered rocky planet" | |
| Librarian 20 | Label: "shelf position 4" + Notes: "book at position 4" | |
| Librarian 27 | Label: "the whole" + Notes: "the thing being subdivided" | |
| Filed away | All 32 catalog entries | One small index card |
The index card for "Earth" might be a compact representation like [proper-noun, planet, geological, mid-position, whole-entity, ...] — a dense encoding that contains enough information for any librarian to reconstruct what they need.
At attention time:
- Librarian 3 expands the index card → Label: "proper noun, object of preposition", Notes: "completes the prepositional phrase"
- Librarian 12 expands the same card → Label: "planet, geological body", Notes: "a layered rocky planet"
- Each librarian applies their own learned expansion to get librarian-specific catalog entries
Why this is different from GQA
GQA reduces storage by sharing — multiple librarians use the same catalog, sacrificing per-librarian specialization. MLA reduces storage by compressing — each librarian still gets their own specialized catalog entries, but they're reconstructed on-demand from a shared compressed index card.
| Approach | Stored per book | Per-librarian entries? | How it saves memory |
|---|---|---|---|
| MHA | 32 labels + 32 notes | Yes, all unique | (no savings — baseline) |
| GQA (8 depts) | 8 labels + 8 notes | Shared within departments | Fewer copies |
| MQA | 1 label + 1 notes | All identical | Single copy |
| MLA | 1 small index card | Yes, reconstructed per-librarian | Compression |
MLA gets the storage efficiency of MQA (or better) with the expressiveness closer to MHA — each librarian can still catalog differently because the expansion step is librarian-specific. The trade-off is extra compute at attention time (the decompression step), but thanks to matrix-multiplication tricks and a smaller working dimension, that cost is more than paid back — leading to much faster inference.
In a way, we can say that MLA helps the model think in a latent space and if the real -> latent -> real space is trained well, it could be equal to or more expressive than MHA while costing a fraction in memory usage. Absolutely crazyyy...
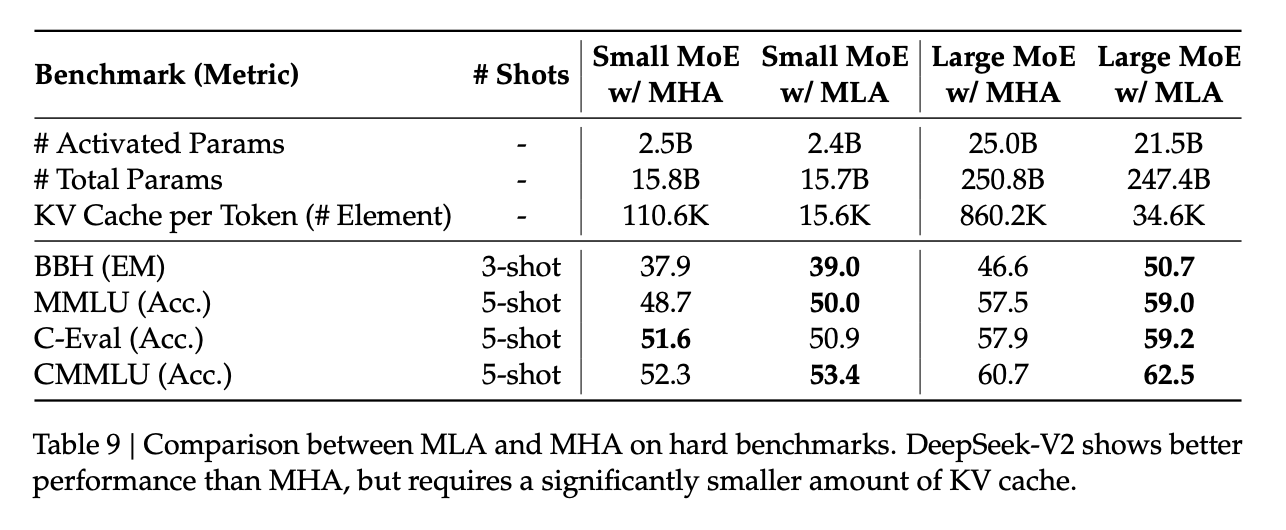
MLA matches or beats MHA while using a tiny fraction of the KV cache — 34.6K vs 860.2K elements per token.
Conclusion
I started with a search engine, decided to wander into a library, and ended up with a room full of specialist librarians. MHA where each librarian has their own catalog, MQA makes them share one, GQA splits them into departments, and MLA hands them a compressed index card to reconstruct from. Same idea, four different answers to the same question — how much catalog can we afford to keep around?
I hope the analogy was useful and the idea clicked a little better. Thanks for reading!